
기계독해, MRC란 무엇일까
업데이트:
제가 진행하려는 프로젝트에, MRC라는 기술을 도입하려고 합니다. MRC를 본격적으로 배우기전에 그래도 아는 척을 좀 하고 싶어서 정리해봅니다 ㅎㅎ.
참고 출처
- 한국어 MRC 연구를 위한 표준 데이터셋(KorQuAD) 소개 및 B2B를 위한 MRC 연구 사례
- ADAMS.ai > MRC based Q&A API
- 자연어 질문에 기계적으로 대답하지 않기
- 기계독해 QA: 검색인가, NLP인가?
- 위 글의 영상 링크! (45분짜리)
‘MRC’ 또는 ‘기계독해’라는 검색어로 구글링 하였습니다. 위 글들을 읽고 정리한 글입니다. 거의 복사해서 수정한 것과 다를 바 없습니다.
첫번째글
평문 Q&A 뿐 아니라 구조화된 문서에 대한 Q&A를 위해 TableQA, TreeQA 모델이 나오게 된 배경 및 차이점 등
LG CNS 연구 내용을 간략히 소개하고, 이를 위한 작업의 일환으로 제작했던 KorQuAD dataset 상세 설명
NAVER Engineering에서 Clova 팀원 분이 설명하신 45분짜리 영상을 보면 이해에 바로 도움이 되실 것 같습니다!
기계독해, MRC란?
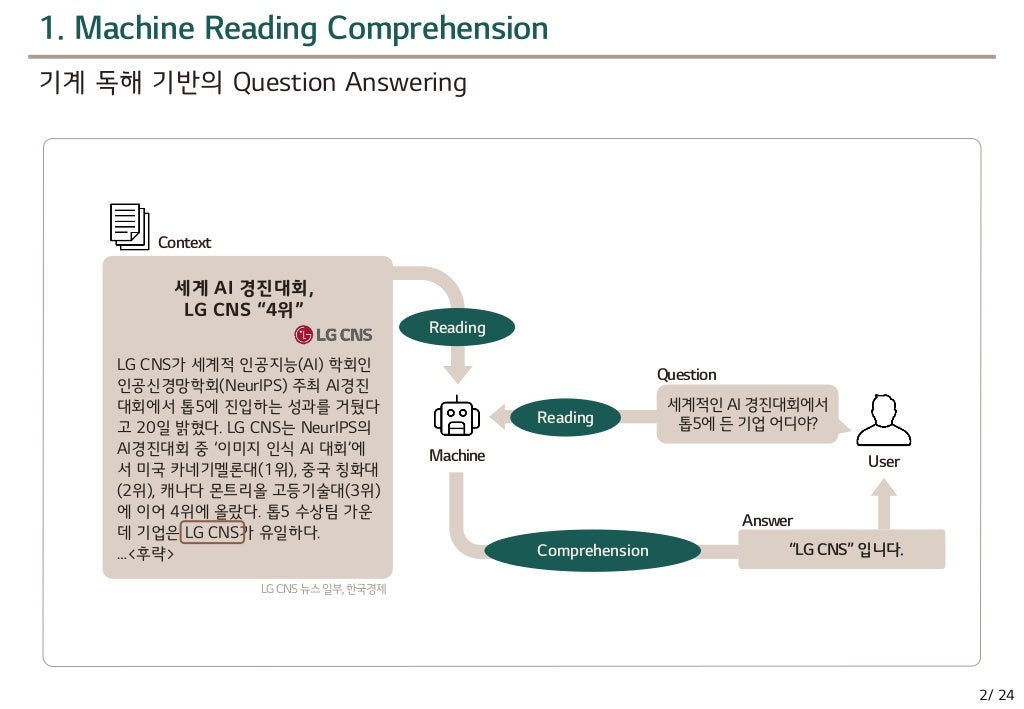
기계독해 Machine Reading Comprehension(MRC) 이렇게 기계한테 질문을 하면 기계가 읽고, 이해해서 답을 한다…?!
검색 + NLP 질문에 대한 적합한 문서를 찾고, NLP로 문서에서 답을 찾아냅니다.
MRC는 주어진 문서를 빠르게 이해하고 문서에 기반하여 질문에 대한 답을 찾아내는 솔루션입니다.
요즘 많이 보급화 된 AI스피커 카카오 미니한테 ‘마우스는 누가 만들었어?’하면, ‘더글라스 앵겔바트’라고 대답을 내놓습니다. 이것도 MRC 기술이라고 합니다.
질문 : “헤이 카카오, 마우스는 누가 만들었어?”
- 사용자의 음성을 음성 인식 기술로 글로 적어냅니다.
- 글로 적어낸 자연어를 인식해 맨 먼저 ‘누구’에 해당하는 단답형 답을 내놓습니다.
- 질문의 요지를 중심으로 외연을 확장합니다.
- ‘마우스를 만든 사람’이 핵심!
- ‘마우스 발명자’, ‘마우스 제작자’, ‘마우스 창제’와 같은 형식으로
- 확장된 외연을 갖고 검색을 합니다.
- 검색 결과 모두를 분석하여 순위를 매깁니다.
- 그 중 최고값을 받은 내용을 답변으로 제시합니다. ( 보통 1~2초 내에 수행해냅니다.)
이 기술은 정형화되지 않은 자연어 문장에서 의미와 의도를 뽑아내는데 핵심적인 역할을 합니다. 지난 수십년 간은 사람이 직접 추출한 결과물에 의존했었습니다.
MRC based QA를 OPEN API로 체험하자
https://www.adams.ai/apiPage?mrcqa
솔트룩스라는 회사에서 제공하는 OPEN API인, ADAMS.ai에 MRC based Q&A API를 웹 상에서 바로 체험해볼 수 있습니다.
Saltlux의 MRC 엔진 참고
- 기계독해 학습 데이터의 구성
- (지문, 질문, 답변)의 쌍으로 구축됩니다.
- 답변이 해당 지문에 위치하는 index 정보를 포함해야 합니다.
단일 학습 모델이 아닌, 문제 해결에 다중 학습 모델을 참조합니다.
대화처리 엔진, 질의응답기술, 지식 자동추출 엔진 과의 연계를 이용하고 있습니다.

Open QA로 활용이 가능합니다. 사용자로부터 문서 입력받지 않아도 이미 보유하고 있는 지식자원에서 사용할 문서를 자동으로 추출합니다. 이를 통해 사용자가 질문만 입력해서 답을 구할 수 있도록 하였습니다.
KorQuAD
KorQuAD는 MRC 모델 중 하나가 아니라, 한국어 MRC를 위한 데이터셋입니다.
현존하는 다양한 영문 데이터
- SQuAD
- MS MARCO
- HotpotQA
KorQuAD의 의의
- MRC 질의응답 과제를 위한 다량의 학습데이터 제공
- 리더보드를 통해 객관적인 기준을 가진 연구 결과 성능 공유의 장 제공
KorQuAD 데이터 수집 과정
한국어 MRC를 위한 데이터 수집이므로, (당연하게도) 단순한 문서 데이터가 아니라, 라벨링 된 데이터를 수집한 것 같습니다.
그래서 데이터 수집의 단계로는
- 대상 문서 수집
- Document Crawling, Extract Passages, Passage Curation
- 공신력 있는 위키백과에서 문서를 따오고, 평문만을 남기고, 정제함
- 질문/답변 생성
- 크라우드 소싱을 통해서 앞의 데이터에 대해서 QA(질문과 답변) 70000+쌍 생성합니다
- 한 사람 > 하나의 문단 > 2-3개 질문 생성
- 하나의 문단 > 3명 할당 = 한 문단 당 총 6-9개 질문 생성
- 질문 어휘의 다양성 유도
- 2차 답변 태깅
- Human performance 측정을 위함
- 2차 작업자가 1차 작업 결과인 문단 & 질문을 보고 답변 영역 선택 (컴퓨터가 답변 영역 선택하듯이)

그래서, 위와 같은 과정으로 모이게 된 KorQuAD의 질문 유형은 이와 같았습니다.
답변 유형은
- 대상 : 55.4%
- 인물 : 23.2%
- 시간 : 8.9%
- 장소 : 7.5%
- 방법 : 4.3%
- 원인 : 0.7% 이었습니다. 이는 영문 표준 데이터와 특성이 유사함이 확인되었습니다.
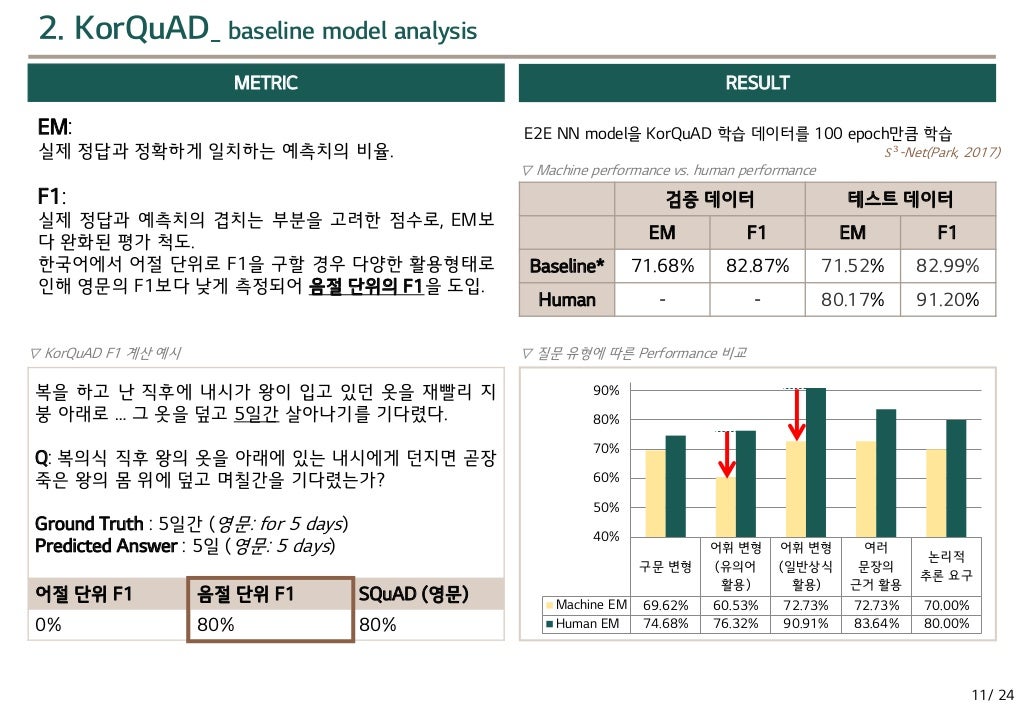
메트릭(Metric) : 측정법을 만들어 내는 엔티티의 속성으로 정해진 수치 또는 분야를 말합니다(NAVER 국어사전)
- EM : 실제 정답과 정확 일치하는 비율
- F1 : 정확 일치 x, 겹치는 부분 고려한 점수(한국어는 어절 단위x, 음절 단위)
MRC for B2B task
현재의 MRC 기술/연구는 정제된 plain text를 대상으로 합니다.
- 구조를 가진 문서는 전처리하여 평문화하여 사용합니다
- 이렇게 되면, 개조식 구조의 상하계층 정보를 반영할 수 없습니다.
- 또한, 표, 목록에 대한 처리가 어렵습니다.
- 제목과 내용이 멀어질 경우 제대로 응답할 수 없다고도 합니다.
하지만, 실제 기업에서 보유한 문서는 구조가 있는 경우가 대부분입니다.
따라서 이를 위한 접근 방법은 다음과 같습니다.
- 구조가 있는 문서를 그대로 반영해서 input으로 사용합시다
- 표, 계층구조, 목록에 대해 최대한 유연하게 처리합시다
- Table에 대한 MRC 가능성을 확인합시다
- 양식을 가진 문서에 대한 MRC 가능성을 확장하여 확인합시다
그래서, 제가 확인한 2019-3월 자료에 따르면 2가지 모델이 예시로 제시되어 있습니다.
- TabQA : 표를 image처럼 행/열 구조를 그대로 받아들이도록 처리
- TreeQA : 양식 문서용 MRC 알고리즘을 위한 input data 처리
TabQA
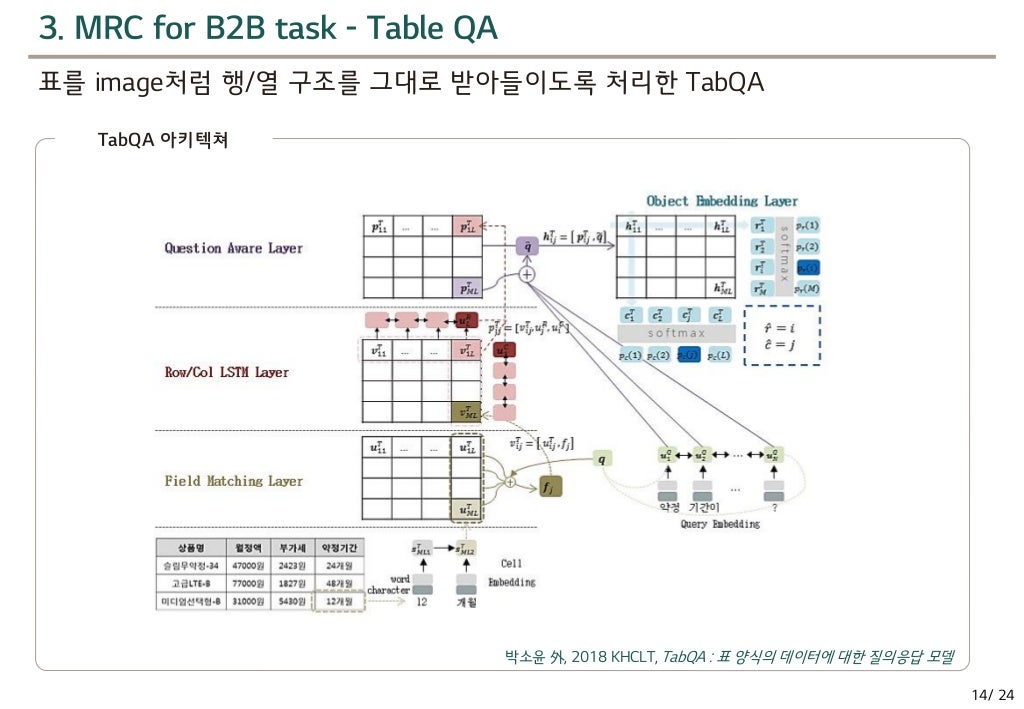
이 모델이 어떤식으로 돌아가는지는 공부를 더해봐야 할 것 같습니다.(LSTM부터 복습..)
TreeQA

계층구조에서 오는 정보를 더 활용할 수 있겠습니다. 평문이면 이런 정보는 다 사라지는 것이니 말입니다.
댓글남기기